
Some folks use the term “automatic speech recognition”, ASR. I don’t like the separation between recognition and understanding, but that’s where the technology stands.
The term ASR encourages thinking about spoken language at a technical level in which purely inductive techniques are used to generate text from an audio signal (which is hopefully some recorded speech!).
As you may know, I am very interested in what many in ASR consider “downstream” natural language tasks. Nonetheless, I’ve been involved with speech since Carnegie Mellon in the eighties. During Haley Systems, I hired one of the Sphinx fellows who integrated Microsoft and IBM speech products with our natural language understanding software. Now I’m working on spoken-language understanding again…
Most common approaches to ASR these days involve deep learning, such as Baidu’s DeepSpeech. If your notion of deep learning means lots of matrix algebra more than necessarily neural networks, then KALDI is also in the running, but it dates to 2011. KALDI is an evolution from the hidden Markov model toolkit, HTK (once owned by Microsoft). Hidden Markov models (HMM) were the basis of most speech recognition systems dating back to the eighties or so, including Sphinx. All of these are open source and freely licensed.
As everyone knows, ASR performance has improved dramatically in the last 10 years. The primary metric for ASR performance is “word error rate” (WER). Most folks think of WER as the percentage of words incorrectly recognized, although it’s not that simple. WER can be more than 1 (e.g., if you come up with a sentence given only noise!). Here is a comparison published in 2011.
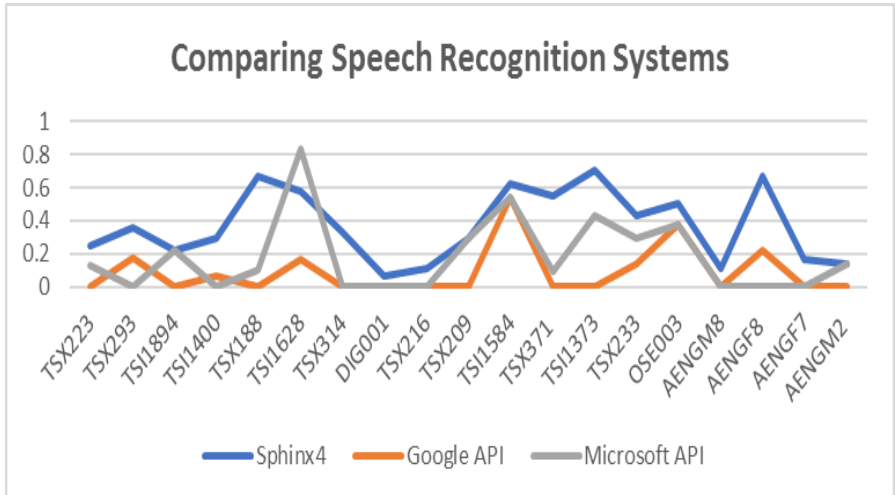
Today, Google, Amazon, Microsoft and others have WER under 10% in many cases. To get there, it takes some talent and thousands of hours of training data. Google is best, Alexa is close, and Microsoft lags a bit in 3rd place. (Click the graphic for the article summarizing Vocalize.io results.)
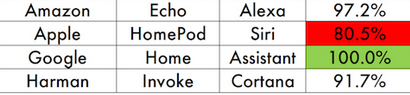
Even more impressive is that Google and Amazon are doing this with far-field microphones. Recognizing far-field speech is much harder than the clean speech that a near-field microphone, such as a high-quality headset microphone used in prior speech recognition benchmarking.
These numbers are better than Google and Amazon perform in regular usage tests, however. For example, using Alexa, you can say “Simon Says”, and it will read back what it thinks it heard. Try a couple 10 word sentences and you’ll probably conclude that Alexa has a WER of 10% or so (again, WER is not a percentage, but everyone treats it that way). Google messes up roughly as much in my experience. I use Cortana (actually, Microsoft Cognitive Services, formerly known as Bing Speech) more and find it generally acceptable, although, as shown above, lagging behind Amazon and Google. I simply don’t know about Siri since I talk to array microphones of various sorts and at various distances, not into an iPhone mic or headset.
I suspect that the numbers above are unrealistically good from Amazon and Google because of the test cases. An utterance like “what time is it”, is pretty short and easy to model with a statistical language model. It also helps that you prime the system by saying, “Alexa” or “Hey, whats-your-name”. More natural dialog without such “keyword spotting” is more challenging. You’re more like to say “uh” in a natural dialog than after you say, “Hey Google”. And, as you get into more natural utterances, they get longer and statistical language modelling does not help as much.
Indeed, statistical language modeling can increase errors. Language models are used in “decoding” the time-series of parameters estimated by an acoustic model which encodes the speech signal. Most ASRs decode using n-gram language models. Roughly speaking, if you have a language model that counts how many times each sequence of 4words is encountered in a corpus you can use it to guide or bias a best-first or beam-search towards a decoding that is “most consistent” with the corpus. If 4 words uttered do not occur in the corpus, decoding needs to estimate that 4-gram’s consistency with the corpus. The most common approach to doing so is by “backing off” to the consistency of 3 words and interpolating with respect to the 4th word. There’s been a lot of work in this area over several decades, but it’s been pretty stable since KenLM, which is used in many state of are deep learning systems. The references of that paper lead to improved Knesser-Ney smoothing for the estimation problem. It is clear to me that Google does better. DeepSpeech uses KenLM and I observe the limitations of Knesser-Ney backoff leading to higher WER. As this has become quite technical, I will spare you the details!
It takes a lot of data to get anywhere near the far-field performance of Google and Amazon (or the near-field performance of Google and Apple), as shown by DeepSpeech numbers (again, click on the image for the PDF).
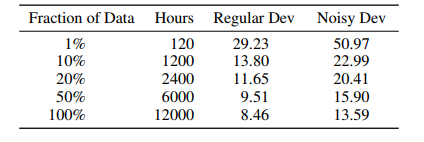
Google has a large edge over Amazon on data, thanks to its Android market penetration and tenure. Amazon had the lead with Echo, but Google has closed that gap this year.
All the rest of us working on ASR have data envy. In the table above, 80% of the data is Baidu’s! It’s hard for anyone to compete with these big players in WER metrics without many times the data that’s publicly available. Fortunately, we have the models made available by Baidu. Unfortunately, anyone who leverages their model is also stuck with it!
Fortunately, there a folks like Daniel Povey. He is behind KALDI (and an open spoken-language resources web site). As you can see on “WER: where are we“, his 2018 paper combining time-delay neural networks (TDNN) with KALDI performs much better than DeepSpeech on the LibriSpeech test. This was accomplished with publicly available data (roughly the same first 20% shown above as used by Baidu). There are some caveats, however. As suggested above, its not just the acoustic model, but the language model impacts word error rate. This paper uses a language model that raises some questions…
Still, there is hope for more open ASR rivaling the leaders in terms of WER. The rest of the question is how well we’ll do at spoken language understanding, which is enabled by low WER, just as natural language understanding (NLU) is enabled by better natural language processing (NLP). It’s great fun to be closing the gap between ever-improving machine learning and more intelligent understanding. Hopefully, this will lead to more valuable intelligent agents than the chatbots that are most likely to claim the Alexa Prize (where by chatbot I mean an agent whose primary goal is merely to converse).