Some folks use the term “automatic speech recognition”, ASR. I don’t like the separation between recognition and understanding, but that’s where the technology stands.
The term ASR encourages thinking about spoken language at a technical level in which purely inductive techniques are used to generate text from an audio signal (which is hopefully some recorded speech!).
As you may know, I am very interested in what many in ASR consider “downstream” natural language tasks. Nonetheless, I’ve been involved with speech since Carnegie Mellon in the eighties. During Haley Systems, I hired one of the Sphinx fellows who integrated Microsoft and IBM speech products with our natural language understanding software. Now I’m working on spoken-language understanding again…
Most common approaches to ASR these days involve deep learning, such as Baidu’s DeepSpeech. If your notion of deep learning means lots of matrix algebra more than necessarily neural networks, then KALDI is also in the running, but it dates to 2011. KALDI is an evolution from the hidden Markov model toolkit, HTK (once owned by Microsoft). Hidden Markov models (HMM) were the basis of most speech recognition systems dating back to the eighties or so, including Sphinx. All of these are open source and freely licensed.
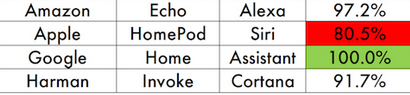
As everyone knows, ASR performance has improved dramatically in the last 10 years. The primary metric for ASR performance is “word error rate” (WER). Most folks think of WER as the percentage of words incorrectly recognized, although it’s not that simple. WER can be more than 1 (e.g., if you come up with a sentence given only noise!). Here is a comparison published in 2011.
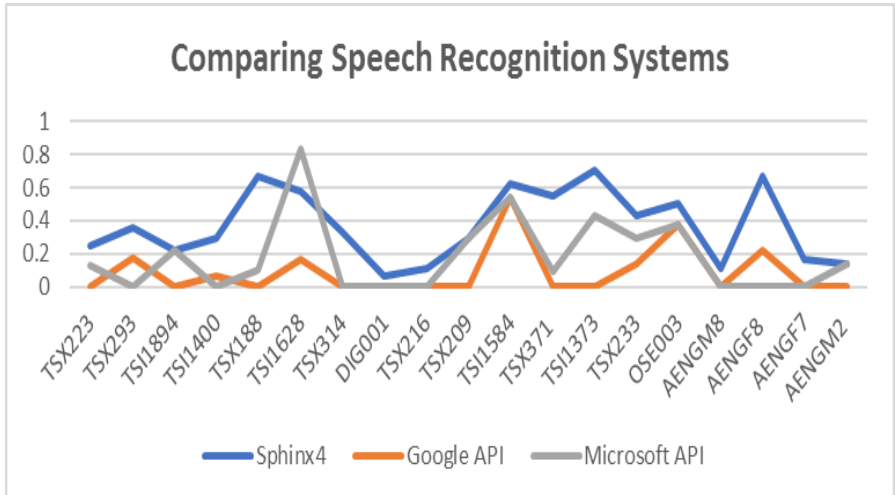
Today, Google, Amazon, Microsoft and others have WER under 10% in many cases. To get there, it takes some talent and thousands of hours of training data. Google is best, Alexa is close, and Microsoft lags a bit in 3rd place. (Click the graphic for the article summarizing Vocalize.io results.)