When I wrote Are Vitamins Subject to Sales Tax, I was addressing the process of translating knowledge expressed in formal documents, like laws, regulations, and contracts, into logic suitable for inference using the Linguist.
Recently, one of my favorite researchers working in natural language processing and reasoning, Luke Zettlemoyer, is among the authors of Entailment-driven Extracting and Editing for Conversational
Machine Reading. This is a very nice turn towards knowledge extraction and inference that improves on superficial reasoning by textual entailment (RTE).
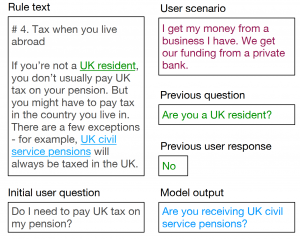
I recommend this paper, which relates to BERT, which is among my current favorites in deep learning for NL/QA. Here is an image from the paper, FYI: